
Für die meisten ist die Wayback Machine ein Nostalgie-Tool: alte URL eingeben, kurz anschauen, wie eine Seite 2009 ausgesehen hat, Tab wieder zu. Im SEO-Alltag kann sie aber deutlich mehr, und in manchen Fällen ist sie sogar die einzige Quelle, die dir noch weiterhilft.
Der Klassiker bei mir: Jemand kommt mit einem Relaunch, der schiefgegangen ist. Die Sichtbarkeit ist eingebrochen, und niemand weiß mehr genau, welche Seiten es vorher überhaupt gab. Spätestens dann ist das Archiv mein erster Anlaufpunkt. Im Folgenden gehe ich durch, was die Wayback Machine ist und wofür sie im SEO wirklich taugt.
WAS IST DIE WAYBACK MACHINE ÜBERHAUPT?
Die Wayback Machine ist ein digitales Web-Archiv, das Schnappschüsse von Webseiten über die Zeit speichert. Betrieben wird sie vom Internet Archive, einer gemeinnützigen Organisation aus San Francisco, die 1996 gegründet wurde. Die öffentliche Wayback Machine selbst gibt es seit 2001. Seitdem hat sie Hunderte Milliarden Versionen von Webseiten gesichert.
Vereinfacht gesagt: Ein Crawler des Internet Archive besucht regelmäßig Webseiten und macht eine Kopie. Diese Kopie kannst du dir später unter web.archive.org anschauen, datiert auf einen bestimmten Tag. So kannst du nachvollziehen, wie eine Seite vor einem Jahr, vor fünf Jahren oder vor dem letzten Relaunch ausgesehen hat.
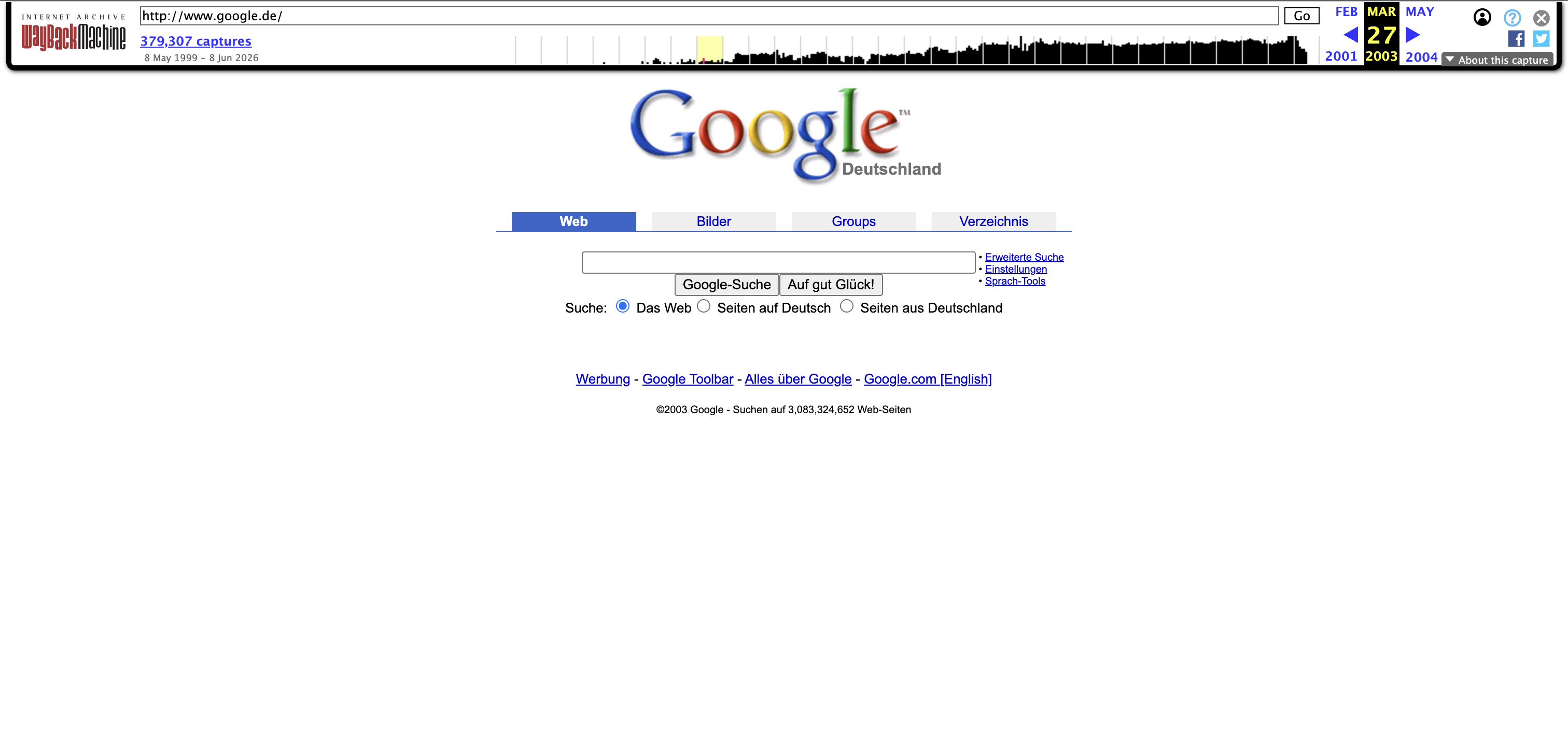
Ein anschauliches Beispiel ist die Google-Startseite: So sah google.de im März 2003 aus, direkt aus dem Archiv abgerufen.
Wichtig zu verstehen: Das Archiv ist nicht vollständig. Nicht jede Seite wird gespeichert, nicht jeder Snapshot ist sauber gerendert, und besonders JavaScript-lastige Seiten sehen im Archiv oft kaputt aus. Trotzdem reicht das, was archiviert wird, für die meisten SEO-Zwecke locker aus.
WARUM IST DIE WAYBACK MACHINE FÜR SEO RELEVANT?
Weil SEO ein Spiel mit der Zeit ist. Rankings entstehen über Jahre, Inhalte verändern sich, Domains wechseln den Besitzer, Relaunches gehen schief. Und in fast all diesen Fällen brauchst du einen Blick in die Vergangenheit, um die Gegenwart zu erklären.
Die Wayback Machine ist dabei die einzige neutrale Quelle, die unabhängig von dir, deinem Kunden oder einem Tool-Anbieter dokumentiert, was wann online war. Genau das macht sie so wertvoll. Hier sind die neun Einsatzgebiete, die sich bei mir am stärksten ausgezahlt haben.
WIE RETTE ICH EINEN SCHIEFGELAUFENEN RELAUNCH?
Das ist für mich der wichtigste Anwendungsfall, und meistens kommt er als Notfall. Nicht der saubere Relaunch, der von Anfang an begleitet wurde, sondern der, der bereits danebengegangen ist. Jemand landet bei mir, weil die Sichtbarkeit nach dem Go-Live eingebrochen ist, und niemand kann mehr genau sagen, welche URLs und Inhalte es vorher überhaupt gab. Bei einem Relaunch (also einer grundlegenden technischen oder inhaltlichen Neuauflage einer Website) geht dieses Wissen regelmäßig verloren: welche URLs vorher existierten, welche Seiten gerankt haben und welche Inhalte auf den alten Seiten standen.
Wenn es keinen alten Crawl gibt (und den gibt es in solchen Fällen fast nie), ist die Wayback Machine oft die einzige Quelle, die die alte Website noch dokumentiert.
Die Wayback Machine schließt diese Lücke:
- Alte URL-Struktur rekonstruieren: Du siehst, welche URLs vor dem Relaunch existierten, und kannst prüfen, ob sie sauber per 301 auf die neuen Ziele weitergeleitet wurden.
- Verlorene Inhalte zurückholen: Wenn beim Relaunch Texte, Ratgeber oder Produktbeschreibungen verschwunden sind, findest du sie im Archiv oft noch im Volltext.
- Interne Verlinkung nachvollziehen: Du erkennst, wie alte Seiten untereinander verlinkt waren, und welche dieser Pfade beim Relaunch gekappt wurden.
- Schema und Metadaten vergleichen: Title-Tags, Meta-Descriptions und strukturierte Daten der alten Version lassen sich gegen die neue Version stellen.
Mein Vorgehen in so einem Fall: Ich ziehe mir die komplette alte URL-Struktur aus dem Archiv (dazu gleich mehr, das geht erstaunlich elegant über die API) und gleiche ab, welche dieser Seiten beim Relaunch verloren gegangen sind oder ins Leere zeigen. Daraus entsteht schnell eine Liste der Baustellen, die den Einbruch erklären, und damit ein konkreter Plan: weiterleiten, wiederherstellen oder bewusst aufgeben.
WIE DIAGNOSTIZIERE ICH RANKING-EINBRÜCHE MIT DEM ARCHIV?
Eine Seite ist über Nacht abgestürzt, und keiner weiß warum? Dann ist das Archiv dein bester Zeuge. Du legst zwei Snapshots nebeneinander: einen aus der Zeit, als die Seite noch gut lief, und einen aus der Zeit nach dem Einbruch.
Worauf ich dabei achte:
- Wurde der Haupttext gekürzt oder ausgetauscht?
- Hat sich der Title-Tag oder die H1 verändert?
- Sind interne Links oder ganze Module verschwunden?
- Wurde die Seite vielleicht von einer eigenständigen URL in eine andere integriert?
Oft liegt die Ursache nicht bei Google, sondern bei einer unscheinbaren Änderung im CMS, die längst vergessen ist. Das Archiv macht solche stillen Eingriffe sichtbar.
WIE NUTZE ICH DIE WAYBACK MACHINE FÜR BACKLINK-RECOVERY?
Backlink-Recovery (also das Zurückgewinnen verloren gegangener Backlinks) ist einer der unterschätztesten Hebel im SEO, und das Archiv ist hier Gold wert.
Das typische Szenario: Eine deiner Seiten hatte starke Backlinks, wurde aber irgendwann gelöscht oder verschoben, ohne dass jemand eine Weiterleitung eingerichtet hat. Der Link zeigt jetzt ins Leere, und die Linkkraft verpufft.
So gehe ich vor:
- Über ein Backlink-Tool (z.B. SISTRIX oder Ahrefs) finde ich verlinkte URLs, die einen 404 zurückgeben.
- Im Archiv schaue ich nach, welcher Inhalt früher auf dieser URL stand.
- Dann entscheide ich: per 301 auf eine passende, noch existierende Seite weiterleiten oder den alten Inhalt rekonstruieren und neu veröffentlichen.
So verwandelst du tote Links wieder in wirksame Ranking-Signale, ganz ohne neuen Linkaufbau.
WIE ANALYSIERE ICH WETTBEWERBER ÜBER DIE ZEIT?
Die meisten Konkurrenzanalysen sind eine Momentaufnahme. Du kannst nachvollziehen, wie sich ein Wettbewerber inhaltlich und strukturell entwickelt hat.
Spannende Fragen, die das Archiv beantwortet:
- Wann hat der Wettbewerber seine wichtigsten Landingpages aufgebaut oder überarbeitet?
- Welche Themen hat er ergänzt, als seine Sichtbarkeit gestiegen ist?
- Hat er Title-Tags, Seitenstruktur oder Content-Tiefe verändert, und wann?
- Welche Seiten hat er irgendwann wieder entfernt (vermutlich, weil sie nicht funktioniert haben)?
Wenn ich einen Sichtbarkeitsverlauf aus einem Tool mit den Archiv-Snapshots überlagere, sehe ich oft sehr genau, welche konkrete Änderung einen Wachstumsschub ausgelöst hat. Das ist deutlich aussagekräftiger als reines Raten.
WIE PRÜFE ICH DIE HISTORIE EINER DOMAIN VOR DEM KAUF?
Expired Domains und alte Domains mit Backlink-Profil sind verlockend, aber riskant. Bevor du Geld in eine Domain steckst (egal ob für ein Projekt oder als Redirect-Quelle), solltest du ihre Vergangenheit kennen.
Im Archiv prüfe ich:
- Thematische Kontinuität: Passt die frühere Nutzung zum geplanten Thema, oder lief darauf irgendwann ein Casino, eine Pharma-Seite oder eine fremdsprachige Spam-Site?
- Brüche im Verlauf: Phasen mit komplett themenfremdem Inhalt sind ein Warnsignal für eine bereits ausgenutzte oder verbrannte Domain.
- Spam-Spuren: Plötzlich japanischer oder russischer Spam-Content auf einer deutschen Domain deutet auf eine Hacking-Phase hin.
Dieser Check dauert zehn Minuten und bewahrt dich vor teuren Fehlkäufen.
Lass uns dein Setup besprechen und ungenutzte Potenziale sichtbar machen.
JETZT ANFRAGE SENDENWIE WEISE ICH NACH, WANN EIN INHALT ZUERST ONLINE WAR?
Bei Verdacht auf Content-Klau ist die Frage entscheidend: Wer hatte den Text zuerst? Die Wayback Machine liefert hier einen datierten, unabhängigen Nachweis, wann ein bestimmter Inhalt auf einer URL erschienen ist.
Das hilft in zwei Situationen:
- Eigener Content wurde kopiert: Du kannst belegen, dass dein Snapshot älter ist als der des Kopierers.
- Du wirst zu Unrecht beschuldigt: Der umgekehrte Fall funktioniert genauso.
Ein juristisch wasserdichter Beweis ist das allein nicht, aber als Indiz und für eine sachliche Argumentation gegenüber Google oder dem anderen Webmaster ist es sehr brauchbar.
WIE LESE ICH DIE ROBOTS.TXT-HISTORIE EINER SEITE?
Die Wayback Machine archiviert auch Dateien wie die robots.txt. Du kannst also nachschauen, wie die Crawling-Regeln einer Domain zu einem bestimmten Zeitpunkt aussahen.
Praktisch wird das, wenn eine Seite irgendwann aus dem Index gefallen ist. Manchmal liegt die Ursache in einer alten robots.txt, die einen ganzen Verzeichnispfad blockiert hat, oft nach einem Relaunch oder einem versehentlich live geschobenen Staging-Setup. Das Archiv zeigt dir, ab wann die Sperre drin war.
WIE NUTZE ICH DAS ARCHIV IM GROSSEN STIL ÜBER DIE API?
Das Internet Archive bietet die sogenannte CDX-API an. Das ist eine Schnittstelle, über die du programmatisch abfragen kannst, welche Snapshots zu einer URL oder einem ganzen Verzeichnis existieren.
Der praktischste Trick daran: Du kannst dir eine Liste aller URLs ziehen, die der Wayback Machine zu einer Domain jemals bekannt waren. Genau das ist Gold wert, wenn kein alter Crawl mehr existiert. Dafür gibst du einfach folgende Adresse in den Browser ein und ersetzt deine-domain.de durch die gewünschte Domain:
https://web.archive.org/cdx/search/cdx?url=deine-domain.de/*&output=text&fl=original&collapse=urlkey
Kurz erklärt, was die Parameter machen:
url=deine-domain.de/*fragt alle bekannten URLs unterhalb der Domain ab.output=textliefert eine schlichte Textliste statt JSON.fl=originalgibt nur die Original-URL aus, ohne Zusatzspalten.collapse=urlkeyentfernt Dubletten, sodass jede URL nur einmal erscheint.
Das Ergebnis ist ein komplettes URL-Set, das der Wayback Machine jemals bekannt war. Genau hier schließt sich der Kreis zur Backlink-Recovery: In so einer Liste tauchen regelmäßig alte Seiten auf, die nie weitergeleitet wurden. Wenn darauf früher Backlinks zeigten, kannst du dir über eine saubere 301-Weiterleitung ein paar davon zurückholen.
Darüber hinaus lässt sich die API für noch mehr automatisieren:
- Snapshot-Zeitpunkte für hunderte URLs auf einmal abfragen.
- Veränderungen einzelner Seiten über die Zeit systematisch vergleichen.
- Die Ergebnisse direkt in ein Workflow-Tool wie n8n oder in ein eigenes Skript füttern.
Gerade in Kombination mit Crawl-Daten aus dem Screaming Frog oder Backlink-Exporten wird das richtig stark. Du baust dir damit eine vollständige Karte der Vergangenheit einer Domain, statt einzeln zu stochern.
Wenn du eine Seite aktiv im Archiv sichern willst, gibt es übrigens die Funktion Save Page Now auf der Startseite von web.archive.org. Praktisch, wenn du eine wichtige Konkurrenzseite festhalten möchtest, bevor sie verändert wird.
WO LIEGEN DIE GRENZEN DER WAYBACK MACHINE?
Damit hier kein falscher Eindruck entsteht: Das Archiv ist mächtig, aber kein Allheilmittel. Die wichtigsten Einschränkungen:
- Lückenhafte Abdeckung: Kleine oder neue Seiten werden seltener oder gar nicht erfasst.
- JavaScript-Probleme: Stark dynamische Seiten rendern im Archiv oft unvollständig oder gar nicht.
- Rückwirkende Entfernung: Wenn eine Domain später eine sperrende
robots.txtsetzt oder der Betreiber die Entfernung beantragt, können auch alte Snapshots verschwinden. - Kein Live-Ranking-Tool: Das Archiv zeigt Inhalte, keine Rankings. Die Verknüpfung zur Sichtbarkeit musst du selbst über deine SEO-Tools herstellen.
Wer das im Hinterkopf behält, wird selten enttäuscht.
FAZIT: EIN ALTES TOOL, DAS IM SEO-ALLTAG IMMER NOCH GLÄNZT
Die Wayback Machine ist kein nettes Spielzeug für nostalgische Momente, sondern ein ernstzunehmendes Recherche-Werkzeug. Sie hilft bei schiefgelaufenen Relaunches, rettet verlorene Backlinks, erklärt Ranking-Einbrüche und schützt dich vor faulen Domain-Käufen. Und das alles kostenlos und unabhängig.
Mein Tipp: Öffne das Archiv beim nächsten Projekt einfach mal ganz bewusst, bevor du loslegst. Du wirst überrascht sein, wie viele Antworten schon in der Vergangenheit liegen.